Duplicate content can hurt your website’s search engine ranking. Rel=’canonical’ is a solution to this issue.
Duplicate content happens when the same content appears on multiple URLs. This confuses search engines and affects your site’s ranking. Rel=’canonical’ helps specify the original content source, guiding search engines to the right URL. This can improve your site’s SEO and user experience.
Understanding and using rel=’canonical’ correctly can prevent duplicate content problems, ensuring your site stays optimized and user-friendly. Let’s delve into how this works and why it’s essential for your website’s health.

Credit: www.youtube.com
Introduction To Duplicate Content
Duplicate content is a common issue that can impact your website’s SEO. Understanding it is crucial for maintaining a healthy site. This section will delve into what duplicate content is and why it matters for your website.
What Is Duplicate Content?
Duplicate content refers to substantial blocks of content within or across domains that match exactly or are very similar. It can occur in various forms:
- Identical content on different pages of the same site
- Content copied from another site
- Product descriptions repeated across multiple pages
Not all duplicate content is malicious or intentional. Sometimes, it happens due to technical issues or site structure. Let’s explore why it’s important to address it.
Why Duplicate Content Matters
Duplicate content can confuse search engines. They struggle to decide which version is more relevant. This can lead to several issues:
- Ranking Issues: Search engines may not know which page to rank. This can dilute the ranking power of your pages.
- Traffic Loss: Duplicate content can split traffic between pages. This reduces the overall page authority.
- Crawl Budget Waste: Search engines waste resources crawling duplicate pages. This can affect the indexing of unique content.
Addressing duplicate content is essential for SEO. One effective method is using the rel="canonical" tag.
| Issue | Impact |
|---|---|
| Ranking Issues | Confusion on which page to rank |
| Traffic Loss | Split traffic between pages |
| Crawl Budget Waste | Resources spent on duplicate pages |

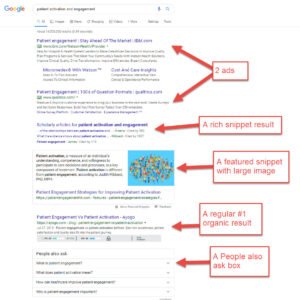
Credit: www.thesempost.com
Common Causes Of Duplicate Content
Duplicate content can harm your website’s search engine rankings. It confuses search engines and splits link equity. Understanding common causes of duplicate content helps you prevent it. Let’s explore some of the common causes.
Url Variations
Different URL structures can create duplicate content. For example, a single product page might have multiple URLs. These variations occur due to session IDs, tracking codes, or sorting parameters. Search engines see these as separate pages, leading to duplicate content issues.
Http Vs. Https
Websites accessible through both HTTP and HTTPS can create duplicate content. Each protocol shows the same content, but search engines treat them as different pages. This creates confusion and affects your site’s SEO performance.
Www Vs. Non-www
Websites available with both WWW and Non-WWW versions can cause duplicate content. For instance, search engines consider “www.example.com” and “example.com” as different websites. This leads to duplicate content problems and can dilute your search rankings.
Impact Of Duplicate Content On Seo
Duplicate content can harm SEO by confusing search engines about which page to rank. Rel=’canonical’ helps direct search engines to the preferred version. This improves ranking and avoids penalties.
Duplicate content can seriously hurt your SEO efforts. Search engines like Google aim to provide the best user experience. They dislike showing the same content multiple times. This issue can lead to penalties, lower rankings, and reduced visibility. Understanding the impact of duplicate content on SEO is crucial. Let’s explore three major areas affected by duplicate content.Search Engine Confusion
Search engines get confused by duplicate content. They struggle to determine which version to index. This confusion can lead to neither version ranking well. Search engines may split link equity between duplicates. This reduces the overall authority of each page.Ranking Dilution
Duplicate content causes ranking dilution. When multiple pages have the same content, they compete against each other. This can lower the ranking of all pages involved. Instead of one strong page, you get several weaker ones. Ranking dilution can be a significant setback for your SEO strategy.User Experience Issues
Users want unique and relevant content. Duplicate content can frustrate them. They may leave your site quickly if they see the same content repeatedly. High bounce rates signal to search engines that your site offers poor user experience. This can further damage your rankings.| Issue | Effect on SEO |
|---|---|
| Search Engine Confusion | Lower rankings due to indexing issues |
| Ranking Dilution | Reduced authority and visibility |
| User Experience Issues | Higher bounce rates and lower rankings |
Introduction To Rel=’canonical’
Duplicate content can confuse search engines. It can impact your site’s SEO. Using Rel=’Canonical’ helps solve this issue. This tag tells search engines the preferred version of a webpage. Let’s explore the Rel=’Canonical’ tag and its importance.
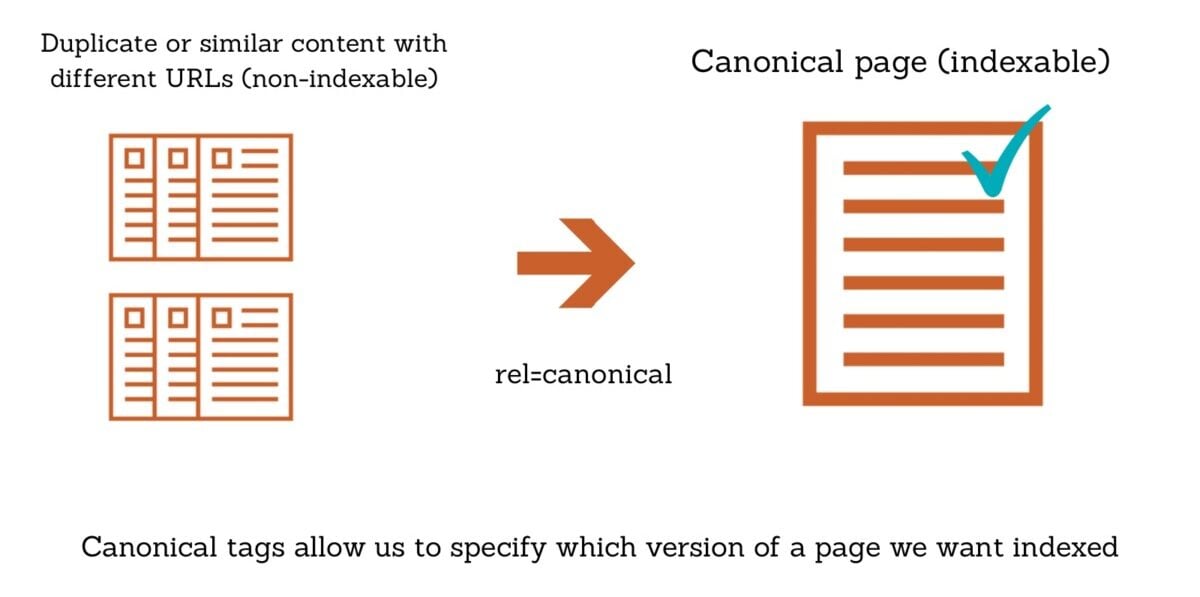
What Is Rel=’canonical’?
Rel=’Canonical’ is an HTML attribute. It specifies the main version of a webpage. This tag prevents duplicate content issues. It guides search engines to the original page. This way, SEO value is concentrated on one page.
Importance Of Canonical Tags
Canonical tags help manage duplicate content. They ensure the main page gets full credit. This improves search engine ranking. Without this tag, search engines may split ranking signals. This can dilute your SEO efforts.
Canonical tags also improve user experience. They ensure users find the right content. This reduces bounce rates. It also helps maintain your site’s authority. Search engines trust sites with clear, unique content.
How To Implement Canonical Tags
Implementing canonical tags is essential for managing duplicate content on your website. Canonical tags help search engines understand which version of a page is the original. This process can improve your site’s SEO performance and avoid penalties from search engines.
Identifying Canonical Urls
First, identify the canonical URL for each page. The canonical URL is the preferred version of a set of duplicate pages. It is the URL you want search engines to index.
To identify the canonical URL, choose the URL with the most value. This could be the URL with the most content, highest traffic, or best user engagement.
Setting Up Canonical Tags
Once you have identified the canonical URLs, it’s time to set up the canonical tags. Add the canonical tag in the HTML head section of the duplicate page.
The tag should look like this:
Replace “https://www.example.com/canonical-url” with your chosen canonical URL. Ensure each duplicate page points to the correct canonical URL.
Common Mistakes To Avoid
Several common mistakes can occur when setting up canonical tags. Do not point all pages to the homepage. This can confuse search engines and hurt your SEO.
Ensure the canonical URL is not blocked by robots.txt. If search engines cannot access the canonical URL, they cannot index it.
Avoid having multiple canonical tags on a single page. This can lead to conflicting signals and indexing issues.
Regularly check your canonical tags for errors. Broken links or incorrect URLs can affect your website’s performance.
Best Practices For Managing Duplicate Content
Managing duplicate content is crucial for maintaining a healthy website. Duplicate content can confuse search engines and hurt your rankings. Using the rel='canonical' tag is a smart way to tell search engines which version of a page is the primary one. Here are some best practices to manage duplicate content effectively.
Consistent Internal Linking
Consistent internal linking helps search engines understand your site’s structure. Always link to the preferred version of a page. For example, if you have both http://example.com/page and http://www.example.com/page, choose one and stick with it.
Here’s how you can do it:
- Use absolute URLs in your internal links.
- Ensure all internal links point to the canonical URL.
- Regularly audit your site to fix inconsistent links.
Parameter Handling
URL parameters can create duplicate content. Parameters like ?sessionid or ?ref=source can make search engines see multiple versions of the same page.
To handle parameters effectively:
- Use the
rel='canonical'tag to point to the main version. - Set up rules in Google Search Console to manage URL parameters.
- Consider using server-side redirects to consolidate URL variations.
Content Syndication
Content syndication involves sharing your content on other sites. This can lead to duplicate content issues. Make sure the original content gets the credit it deserves.
Follow these steps:
- Use the
rel='canonical'tag on syndicated content. - Ensure the original publisher includes a canonical link back to your site.
- Consider providing a short summary with a link to the original article.
By following these best practices, you can effectively manage duplicate content. This helps in maintaining a clean and efficient website structure.
Tools For Detecting Duplicate Content
Detecting duplicate content is crucial for maintaining a healthy SEO strategy. Duplicate content can harm your website’s rankings and confuse search engines. Fortunately, several tools can help you identify and manage duplicate content. These tools assist in ensuring your content remains unique and authoritative.
Google Search Console
Google Search Console is a free tool provided by Google. It helps webmasters monitor and maintain their site’s presence in Google Search results. This tool allows you to identify duplicate content issues. Navigate to the “Coverage” report to see if Google has flagged any duplicate content on your site. You can also use the “Performance” report to check which pages might be suffering from duplicate content issues.
Third-party Seo Tools
Third-party SEO tools offer advanced features for detecting duplicate content. Some popular options include SEMrush, Ahrefs, and Moz. These tools provide detailed reports on duplicate content across your site. They also offer insights into your competitors’ content strategies. Using these tools, you can quickly identify and resolve duplicate content issues.
Another useful tool is Copyscape. Copyscape helps you find instances of content duplication across the web. By entering a URL, you can see if any other sites are using your content without permission. This helps protect your original content and maintain your site’s authority.
Siteliner is another excellent tool for detecting internal duplicate content. It scans your website and highlights any pages with similar content. This helps you pinpoint and correct issues that could harm your SEO efforts.
Case Studies And Examples
Dealing with duplicate content can be challenging. The rel=’canonical’ tag is a useful tool. It helps search engines understand which version of a page is the original. Understanding its real-world application can be enlightening. Below, we explore case studies and examples.
Successful Canonical Tag Usage
One e-commerce site had multiple product pages. Each page had slight variations. This led to duplicate content issues. They used rel=’canonical’ to point to the main product page. The result? Their search rankings improved. They saw more organic traffic. The canonical tag clarified the preferred URL for search engines. This reduced the risk of duplicate content penalties.
Recovering From Duplicate Content Issues
A blog site faced duplicate content issues. They had many similar posts. This confused search engines. Their rankings dropped. They implemented the rel=’canonical’ tag. This told search engines which post to index. Slowly, their rankings recovered. Their organic traffic increased. The canonical tag helped streamline their content. This made their site more SEO-friendly.
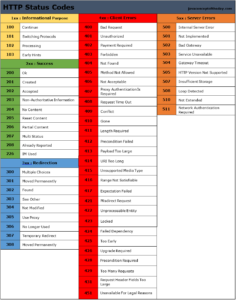
Credit: www.seerinteractive.com
Frequently Asked Questions
What Is Duplicate Content?
Duplicate content refers to identical or very similar content appearing on multiple web pages. This can confuse search engines and impact SEO rankings.
Why Is Duplicate Content Bad For Seo?
Duplicate content can split ranking signals and dilute the authority of a page. This can negatively impact search engine rankings and visibility.
How Does Rel=”canonical” Help?
The rel=”canonical” tag tells search engines which version of a page is the preferred one. This helps consolidate ranking signals.
Can Rel=”canonical” Fix Duplicate Content Issues?
Yes, using rel=”canonical” can help address duplicate content issues. It directs search engines to the original content.
Conclusion
Understanding duplicate content and using rel=’canonical’ is crucial. It helps improve your SEO. Avoid duplicate content to prevent penalties. Rel=’canonical’ guides search engines to the main page. This boosts your website’s ranking. Keep your content unique and clear. Use these techniques to enhance your site’s visibility.
Your audience will find relevant information easily. Stay consistent with these practices. This ensures better performance and search engine trust.

Sofia Grant is a business efficiency expert with over a decade of experience in digital strategy and affiliate marketing. She helps entrepreneurs scale through automation, smart tools, and data-driven growth tactics. At TaskVive, Sofia focuses on turning complex systems into simple, actionable insights that drive real results.